###6.4 缓冲区溢出漏洞
概述
缓冲区溢出是指当计算机向缓冲区内填充数据位数时超过了缓冲区本身的容量,溢出的数据覆盖在合法数据上。理想的情况是:程序会检查数据长度,而且并不允许输入超过缓冲区长度的字符。但是绝大多数程序都会假设数据长度总是与所分配的储存空间相匹配,这就为缓冲区溢出埋下隐患。操作系统所使用的缓冲区,又被称为“堆栈”,在各个操作进程之间,指令会被临时储存在“堆栈”当中,“堆栈”也会出现缓冲区溢出。
数据
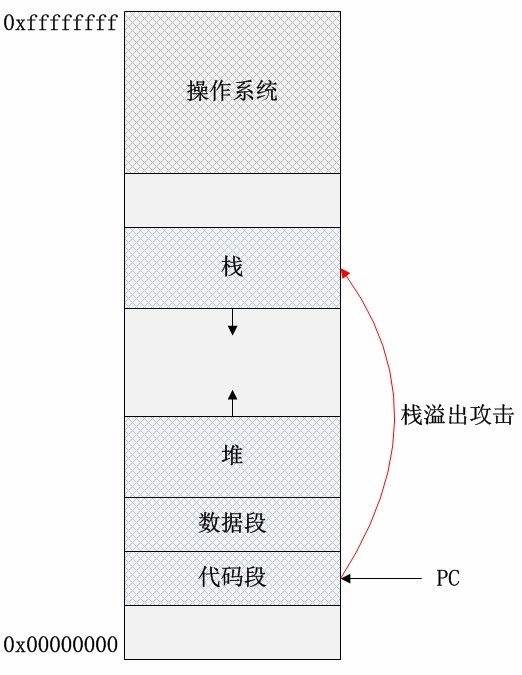
此图是进程地址空间分布的简单表示。代码存储了用户程序的所有可执行代码,在程序正常执行的情况下,程序计数器(PC指针)只会在代码段和操作系统地址空间(内核态)内寻址。数据段内存储了用户程序的全局变量,文字池等。栈空间存储了用户程序的函数栈帧(包括参数、局部数据等),实现函数调用机制,它的数据增长方向是低地址方向。堆空间存储了程序运行时动态申请的内存数据等,数据增长方向是高地址方向。除了代码段和受操作系统保护的数据区域,其他的内存区域都可能作为缓冲区,因此缓冲区溢出的位置可能在数据段,也可能在堆、栈段。如果程序的代码有软件漏洞,恶意程序会“教唆”程序计数器从上述缓冲区内取指,执行恶意程序提供的数据代码!本文分析并实现栈溢出攻击方式。
函数栈帧
栈的主要功能是实现函数的调用。因此在介绍栈溢出原理之前,需要弄清函数调用时栈空间发生了怎样的变化。每次函数调用时,系统会把函数的返回地址(函数调用指令后紧跟指令的地址),一些关键的寄存器值保存在栈内,函数的实际参数和局部变量(包括数据、结构体、对象等)也会保存在栈内。这些数据统称为函数调用的栈帧,而且是每次函数调用都会有个独立的栈帧,这也为递归函数的实现提供了可能。
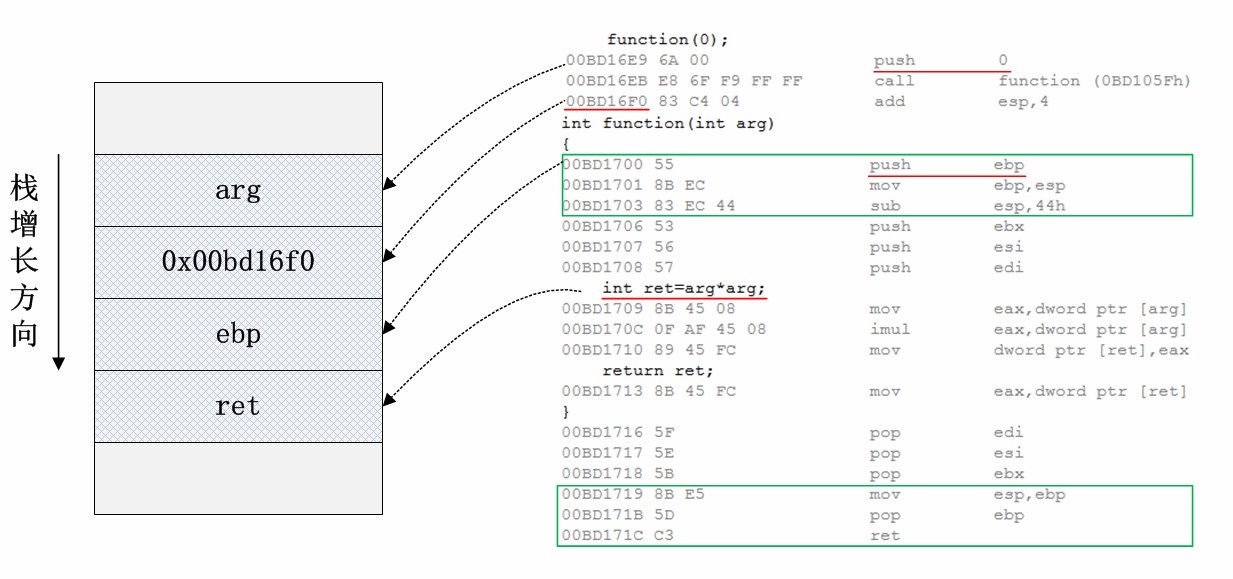
如图所示,我们定义了一个简单的函数function,它接受一个整形参数,做一次乘法操作并返回。当调用function(0)时,arg参数记录了值0入栈,并将call function指令下一条指令的地址0x00bd16f0保存到栈内,然后跳转到function函数内部执行。每个函数定义都会有函数头和函数尾代码,如图绿框表示。因为函数内需要用ebp保存函数栈帧基址,因此先保存ebp原来的值到栈内,然后将栈指针esp内容保存到ebp。函数返回前需要做相反的操作——将esp指针恢复,并弹出ebp。这样,函数内正常情况下无论怎样使用栈,都不会使栈失去平衡。
之所以会有缓冲区溢出的可能,主要是因为栈空间内保存了函数的返回地址。该地址保存了函数调用结束后后续执行的指令的位置,对于计算机安全来说,该信息是很敏感的。如果有人恶意修改了这个返回地址,并使该返回地址指向了一个新的代码位置,程序便能从其它位置继续执行。
栈溢出基本原理
上边给出的代码是无法进行溢出操作的,因为用户没有“插足”的机会。但是实际上很多程序都会接受用户的外界输入,尤其是当函数内的一个数组缓冲区接受用户输入的时候,一旦程序代码未对输入的长度进行合法性检查的话,缓冲区溢出便有可能触发!比如下边的一个简单的函数。
void fun(unsigned char *data)
{
unsigned char buffer[BUF_LEN];
strcpy((char*)buffer,(char*)data);//溢出点
}
这个函数没有做什么有“意义”的事情(这里主要是为了简化问题),但是它是一个典型的栈溢出代码。在使用不安全的strcpy库函数时,系统会盲目地将data的全部数据拷贝到buffer指向的内存区域。buffer的长度是有限的,一旦data的数据长度超过BUF_LEN,便会产生缓冲区溢出。
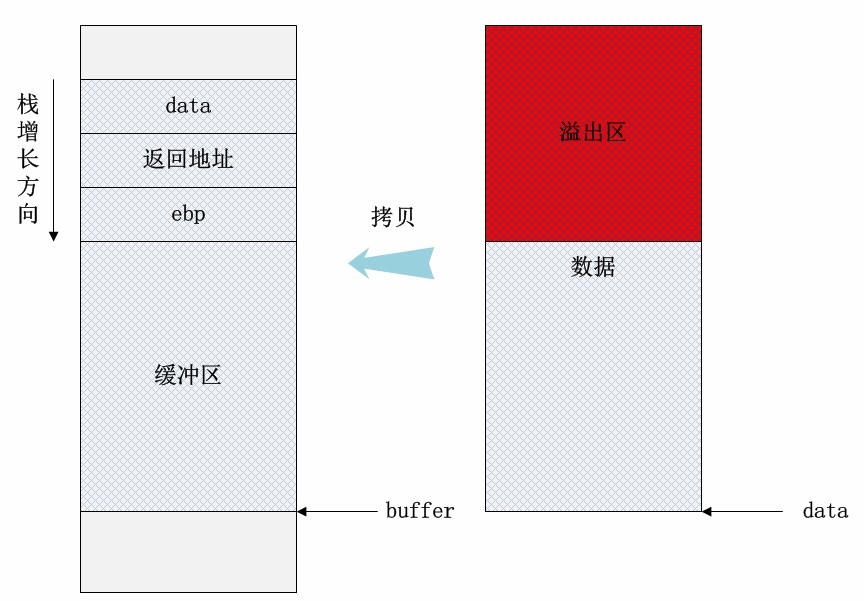
由于栈是低地址方向增长的,因此局部数组buffer的指针在缓冲区的下方。当把data的数据拷贝到buffer内时,超过缓冲区区域的高地址部分数据会“淹没”原本的其他栈帧数据,根据淹没数据的内容不同,可能会有产生以下情况:
1、淹没了其他的局部变量。如果被淹没的局部变量是条件变量,那么可能会改变函数原本的执行流程。这种方式可以用于破解简单的软件验证。
2、淹没了ebp的值。修改了函数执行结束后要恢复的栈指针,将会导致栈帧失去平衡。
3、淹没了返回地址。这是栈溢出原理的核心所在,通过淹没的方式修改函数的返回地址,使程序代码执行“意外”的流程!
4、淹没参数变量。修改函数的参数变量也可能改变当前函数的执行结果和流程。
5、淹没上级函数的栈帧,情况与上述4点类似,只不过影响的是上级函数的执行。当然这里的前提是保证函数能正常返回,即函数地址不能被随意修改(这可能很麻烦!)。
如果在data本身的数据内就保存了一系列的指令的二进制代码,一旦栈溢出修改了函数的返回地址,并将该地址指向这段二进制代码的其实位置,那么就完成了基本的溢出攻击行为。
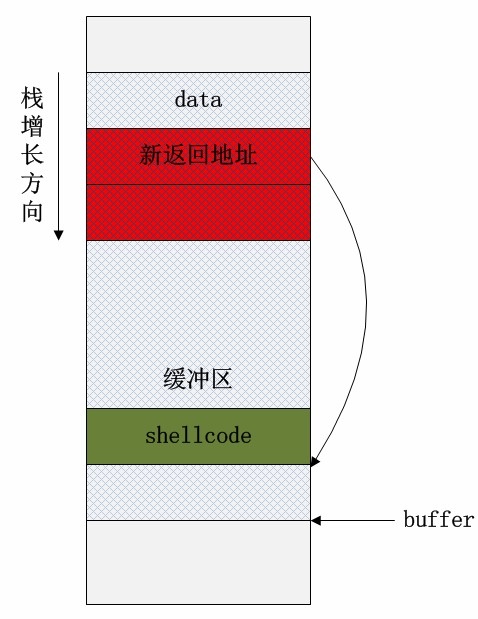
通过计算返回地址内存区域相对于buffer的偏移,并在对应位置构造新的地址指向buffer内部二进制代码的其实位置,便能执行用户的自定义代码!这段既是代码又是数据的二进制数据被称为shellcode,因为攻击者希望通过这段代码打开系统的shell,以执行任意的操作系统命令——比如下载病毒,安装木马,开放端口,格式化磁盘等恶意操作。
防范方法
缓冲区溢出攻击占了远程网络攻击的绝大多数,这种攻击可以使得一个匿名的Internet用户有机会获得一台主机的部分或全部的控制权。如果能有效地消除缓冲区溢出的漏洞,则很大一部分的安全威胁可以得到缓解。
有四种基本的方法保护缓冲区免受缓冲区溢出的攻击和影响。
1.通过操作系统使得缓冲区不可执行,从而阻止攻击者植入攻击代码。
2.强制写正确的代码的方法。
3.利用编译器的边界检查来实现缓冲区的保护。这个方法使得缓冲区溢出不可能出现,从而完全消除了缓冲区溢出的威胁,但是相对而言代价比较大。
4.一种间接的方法,这个方法在程序指针失效前进行完整性检查。虽然这种方法不能使得所有的缓冲区溢出失效,但它能阻止绝大多数的缓冲区溢出攻击。分析这种保护方法的兼容性和性能优势。
参考:_https://www.cnblogs.com/fanzhidongyzby/p/3250405.html_
更新时间:2023-04-12 16:17